
Model optimization is a critical step in deploying machine learning and deep learning models into real-world environments. As organizations move from experimentation to production—especially with large language models (LLMs) and generative AI—the need to balance model performance, latency, memory usage, and cost becomes unavoidable.
This guide provides a structured, practical overview of model optimization, covering core techniques, benefits, trade-offs, and a step-by-step optimization process.
What Is Model Optimization?
Model optimization refers to a set of techniques used to improve the efficiency of an AI model without significantly degrading its accuracy. The goal is to reduce model size, memory footprint, and inference latency while maintaining acceptable model performance.
Optimization can be applied during or after model training, and it often involves modifying model parameters, model weights, or numerical representations such as floating-point precision. These techniques are widely used in machine learning models, deep learning models, and neural networks, particularly when deploying to edge devices, mobile devices, or resource-constrained environments.
Why Is Model Optimization Important?
Unoptimized models are often too large, slow, or expensive for production use. As models scale, especially in LLMs and generative AI, optimization becomes essential to ensure:
- Lower latency for real-time applications
- Reduced memory usage and memory footprint
- Compatibility with GPU, CPU, and specialized accelerators
- Lower infrastructure price and operational cost
- Faster iteration in the development workflow
In practical use cases—such as computer vision, conversational AI, and API-based inference—optimized models enable high-performance execution without overprovisioning hardware.
Types of Model Optimization
Model optimization techniques vary in complexity and impact. Below are the most widely used approaches.
Quantization
Quantization reduces the numerical precision of model weights and activations, typically converting floating-point values (FP32) into lower precision formats such as INT8.
Key benefits:
- Smaller model size
- Faster inference
- Reduced memory usage
Common approaches include post-training quantization and quantization-aware training, both supported in frameworks like TensorFlow and PyTorch.
Full Integer Quantization
Full integer quantization converts all model parameters and computations—including activations—to integer formats. This technique is especially useful for edge devices and mobile devices that lack floating-point acceleration.
Trade-offs include:
- Potential drop in model accuracy
- Requires representative training data for calibration
Pruning
Pruning removes redundant or low-importance neurons, connections, or filters from a neural network. By reducing the number of model parameters, pruning creates a smaller model that is faster to run.
Pruning strategies may be:
- Structured (removing entire channels or layers)
- Unstructured (removing individual weights)
Clustering
Clustering groups similar model weights together and forces them to share values. This reduces the number of unique parameters stored in memory and improves compression.
Clustering is often combined with quantization for additional gains in model size reduction.
Why Should Models Be Optimized?
Size Reduction
Large models consume excessive storage and memory. Optimization techniques compress the model, making it easier to deploy, version, and distribute—especially when models are stored in GitHub, accessed via APIs, or deployed across environments.
Latency Reduction
Optimized models execute faster, reducing inference latency. This is critical for real-time and interactive use cases, such as chatbots, fraud detection, and recommendation systems.
Accelerator Compatibility
Many accelerators require specific data formats. Optimization ensures compatibility with GPUs, TPUs, and inference accelerators by aligning model formats and operations with hardware constraints.
What Are the Trade-offs of Model Optimization?
Every optimization introduces trade-offs. Understanding them is essential for responsible deployment.
Common trade-offs include:
- Reduced model accuracy due to lower precision
- Increased complexity in the optimization process
- Additional validation and metrics tracking
- Longer development iteration cycles
For example, aggressive quantization may speed up inference but degrade accuracy on edge cases. Pruning may remove parameters critical for certain predictions. These trade-offs must be evaluated against business and technical requirements.
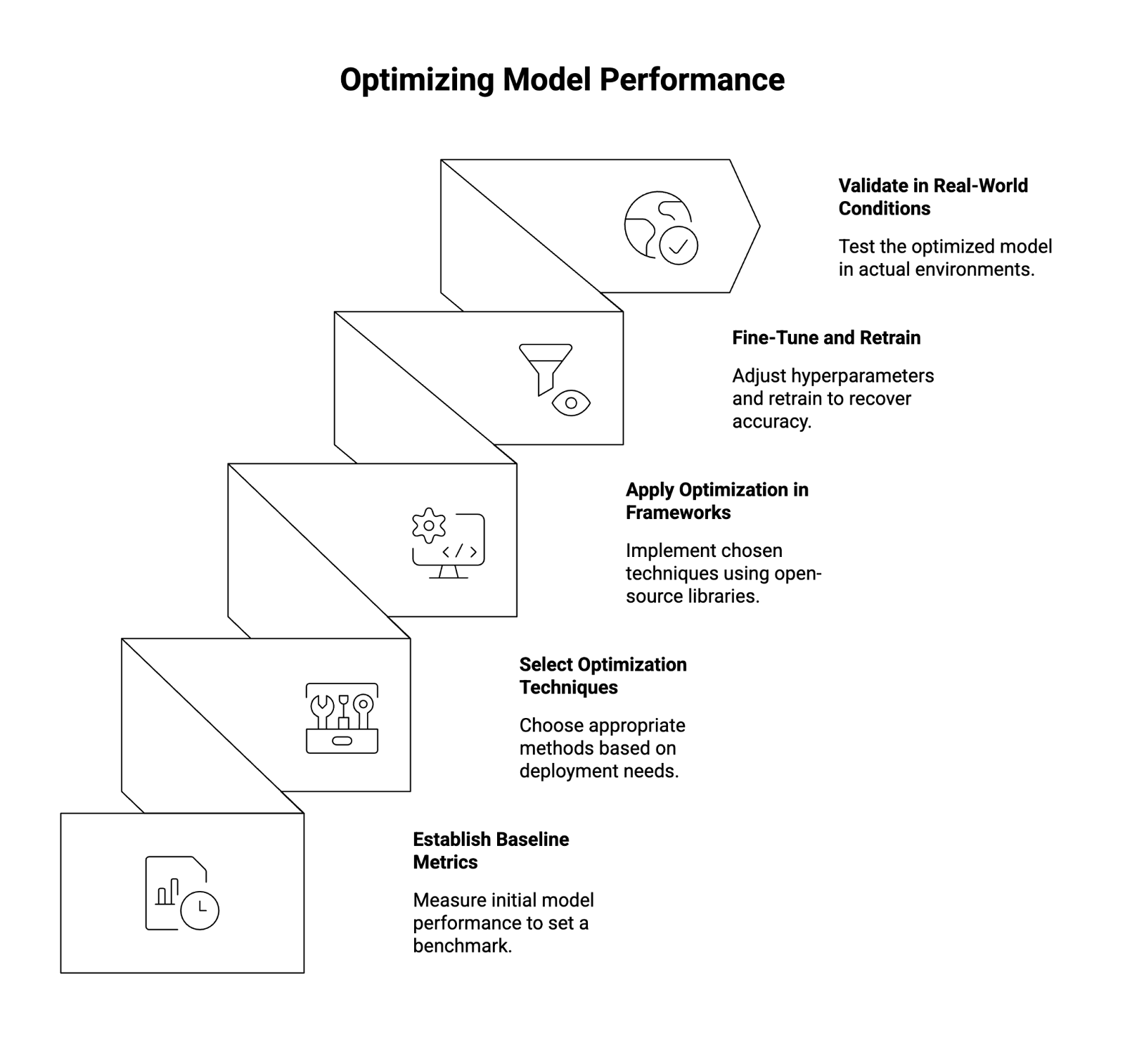
How to Optimize Your Model
A structured optimization workflow helps minimize risk while maximizing performance gains.
Step 1: Establish Baseline Metrics
Before optimization, measure:
- Model accuracy
- Latency
- Memory usage
- GPU or CPU utilization
These metrics provide a baseline for comparison.
Step 2: Select Optimization Techniques
Choose techniques based on your deployment environment:
- Quantization for latency and memory reduction
- Pruning for simplifying large neural networks
- Knowledge distillation to train a smaller model from a larger one
Step 3: Apply Optimization in Frameworks
Use open-source tools and libraries:
- PyTorch (quantization-aware training, pruning utilities)
- TensorFlow (post-training quantization, full integer quantization)
Most workflows are implemented in Python and integrate seamlessly with existing model training pipelines.
Step 4: Fine-Tune and Retrain
After optimization, apply fine-tuning using representative datasets to recover lost accuracy. Adjust hyperparameters, monitor gradients, and retrain across multiple epochs if necessary.
Step 5: Validate in Real-World Conditions
Test the optimized model in real-world environments:
- Edge or mobile devices
- Production APIs
- High-throughput inference systems
Track performance across key metrics and ensure reliability before full deployment.
Conclusion
Model optimization is no longer optional—it is a foundational requirement for deploying scalable, cost-effective, and high-performance AI systems. By applying the right combination of quantization, pruning, clustering, and training strategies, organizations can significantly reduce latency, memory usage, and infrastructure costs while maintaining acceptable accuracy.
As AI systems grow in complexity, optimization will remain a core capability for teams working with modern machine learning and deep learning models.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.