
What is Model Monitoring?
Model monitoring refers to the continuous process of observing, measuring, and analyzing the behavior and performance of machine learning models once they are deployed into production. Unlike development and training phases, where datasets and metrics are controlled, production environments are dynamic. Real-world production data introduces new challenges such as data drift, prediction drift, and changes in data distributions that can degrade model quality over time.
The goal of monitoring is to ensure that an ML model behaves consistently, provides accurate model outputs, and maintains trustworthiness across its entire lifecycle. Effective model monitoring relies on tools, dashboards, and metrics to track changes in input data, feature values, and ground truth labels as they become available.
In short, model monitoring is the backbone of modern MLOps, enabling organizations to maintain healthy models in real-world workflows.
Why Is Model Monitoring Important?
Deploying an AI or machine learning model is not the end of the journey—it’s the beginning of a long-term workflow. Without proper monitoring, models are at risk of producing unreliable or biased outputs due to:
- Data Drift: Shifts in input data compared to the training data baseline. For example, a classification model trained on 2022 financial transactions may struggle with 2025 data trends.
- Concept Drift: Changes in the relationship between features and target outcomes (e.g., customer behavior evolving).
- Prediction Drift: Differences between predicted model outputs and observed ground truth labels.
Consequences of failing to monitor include reduced model performance, inaccurate predictions, compliance violations, and reputational risks in real-world use cases like fraud detection, recommendation systems, or LLMs used in generative AI applications.
Monitoring allows data scientists and engineers to:
- Detect data quality issues in data pipelines.
- Troubleshoot and debug degraded models.
- Schedule retraining when performance metrics cross thresholds.
- Automate alerts and notifications when issues arise.
What is the Difference Between Model Validation and Model Monitoring?
Although related, validation and monitoring serve different roles in the model development and deployment process:
- Model Validation: Occurs before deployment. It tests whether a trained ML model meets performance and compliance requirements using hold-out test sets, cross-validation, and performance metrics such as RMSE, accuracy, or AUC. Validation ensures models are production-ready.
- Model Monitoring: Happens after deployment. It continuously tracks the production model against changing data sources and real-world conditions. Monitoring identifies whether retraining or updates are needed when schema changes, feature values drift, or latency increases.
Think of validation as a pre-flight check and monitoring as ongoing aircraft instrumentation during flight.
What is the Difference Between Model Evaluation and Model Monitoring?
- Model Evaluation: A one-time measurement of model performance during model training or experimentation. For example, comparing classification models with different datasets and hyperparameters. Evaluation is retrospective and controlled.
- Model Monitoring: A forward-looking, continuous monitoring process. It checks the deployed AI model against streaming production data using live dashboards, drift detection tests (e.g., Kolmogorov-Smirnov, Jensen-Shannon divergence), and anomaly detection.
In essence, evaluation measures quality at a moment in time, while monitoring ensures model behavior remains stable in production environments.
What Are the Three Main Types of Monitoring?
- Data Monitoring
- Tracks input data, feature values, and data distributions.
- Detects schema changes, missing values, or new data types.
- Identifies data quality issues in upstream pipelines or feature stores.
- Performance Monitoring
- Compares model predictions with actual ground truth to measure metrics like accuracy, precision, recall, or RMSE.
- Highlights prediction drift and concept drift over time.
- Helps determine when retraining is necessary.
- Operational Monitoring
- Tracks infrastructure dependencies like latency, throughput, and resource consumption on platforms such as NVIDIA GPUs or cloud clusters.
- Ensures APIs and ml pipelines deliver predictions in real-time without failure.
- Monitors versioning of the production model, ensuring rollbacks if regressions occur.
Together, these monitoring layers provide full observability of ML models.
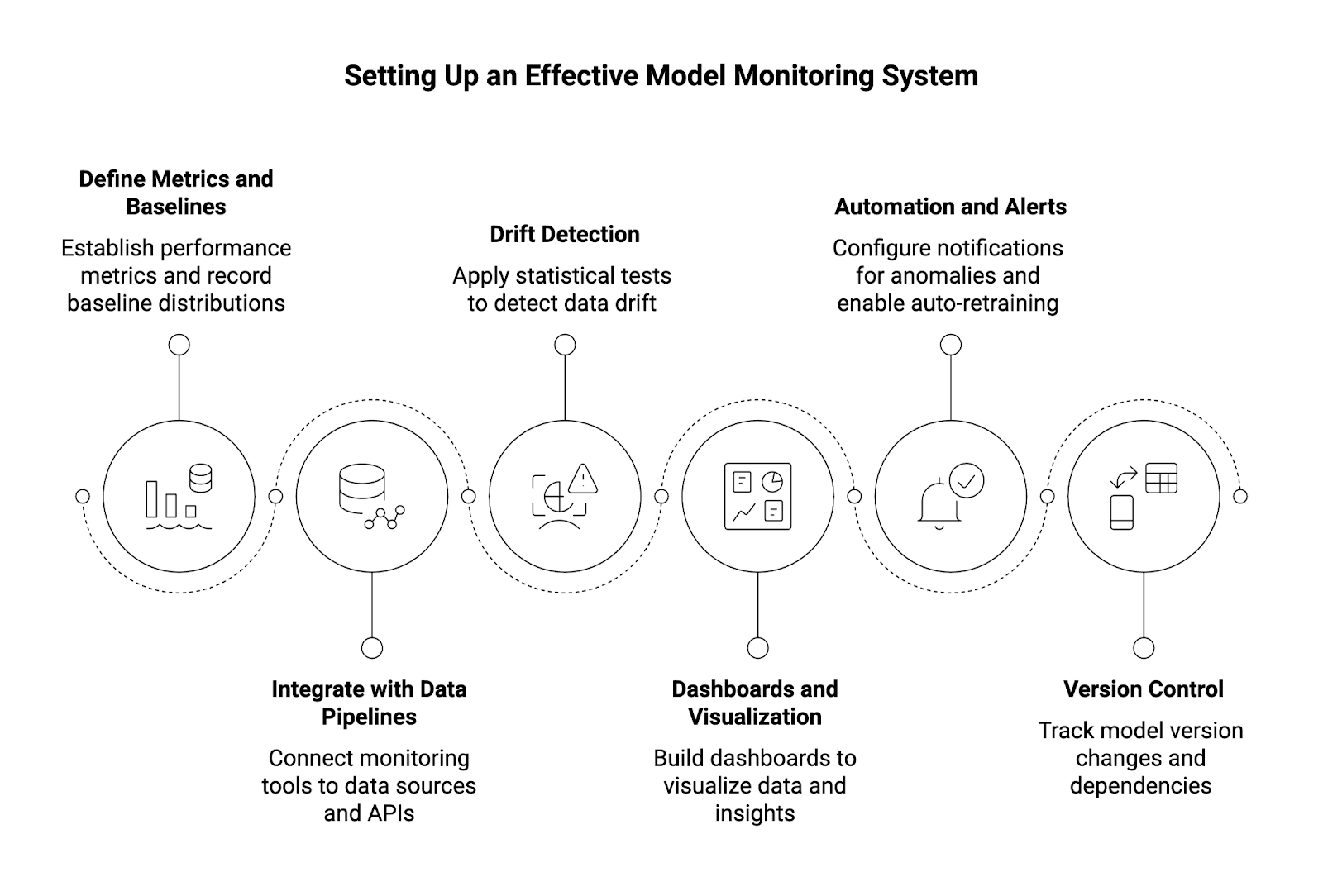
How Can I Set Up an Effective Model Monitoring System?
Setting up monitoring requires both technical integration and process design. Here’s a step-by-step guide:
- Define Metrics and Baselines
- Establish performance metrics (e.g., F1-score, RMSE).
- Record baseline distributions from the training dataset.
- Integrate with Data Pipelines
- Connect monitoring tools to data sources and APIs.
- Capture model inputs and model outputs in a structured log.
- Drift Detection
- Apply statistical tests like Kolmogorov-Smirnov for tabular data or Jensen-Shannon divergence for categorical distributions.
- Use embeddings for generative AI or LLM drift detection.
- Dashboards and Visualization
- Build dashboards in Python or use templates from MLOps platforms.
- Visualize subset analysis, feature attribution, and skew detection.
- Automation and Alerts
- Configure notifications for anomalies in data quality, performance degradation, or latency spikes.
- Enable auto-retraining workflows where thresholds are exceeded.
- Version Control
- Track model version changes, dependencies, and updates to maintain reproducibility.
What Are the Best Practices for Model Monitoring?
To maintain resilient, high-quality AI systems, organizations should adopt the following best practices:
- Continuous Monitoring: Treat monitoring as an ongoing process, not a one-time task.
- Align With Use Cases: Tailor monitoring workflows to specific real-world use cases (e.g., fraud detection requires lower latency than recommendation systems).
- Automate at Scale: Use MLOps pipelines to automate drift detection, retraining, and notifications.
- Leverage Observability: Incorporate logs, dashboards, and metrics into a single monitoring platform for end-to-end visibility.
- Monitor Model Dependencies: Track data sources, libraries, and infrastructure to prevent hidden failures.
- Debug and Troubleshoot Efficiently: Use tools that allow drill-down into feature values, subset performance, or workflow bottlenecks.
- Account for Different Data Types: Apply different checks for tabular data, images, or text embeddings.
- Ensure Governance: Document monitoring results for compliance and regulatory audits.
- Feedback Loop Integration: Use monitoring data to guide model development and future training data collection.
- Optimize Performance: Continuously refine thresholds, metrics, and retraining schedules to ensure peak model behavior.
Conclusion
Model monitoring is not just about observing models—it is about ensuring reliability, compliance, and adaptability of AI systems in production. As data scientists and engineers face evolving challenges with LLMs, generative AI, and large-scale data pipelines, monitoring becomes central to sustaining model quality and business trust.
By combining statistical drift detection, operational monitoring, and automated MLOps workflows, organizations can proactively monitor models, detect issues early, and optimize outcomes across the AI lifecycle.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.