
What is a Model Inversion Attack?
Model inversion attacks are a class of privacy attacks in artificial intelligence where adversaries exploit the information encoded within machine learning models to reconstruct sensitive attributes or even approximate entire entries from the training dataset.
Instead of targeting the raw data directly, attackers use the trained model itself as a vulnerability. By systematically analyzing its outputs—whether in the form of confidence scores, predictions, or gradients—they can uncover patterns that reveal private data.
The concept gained attention after Fredrikson et al. (IEEE, 2015) showed that attackers could use facial recognition models to partially reconstruct images of individuals in the training data. This early demonstration made it clear that trained models themselves can leak sensitive information.
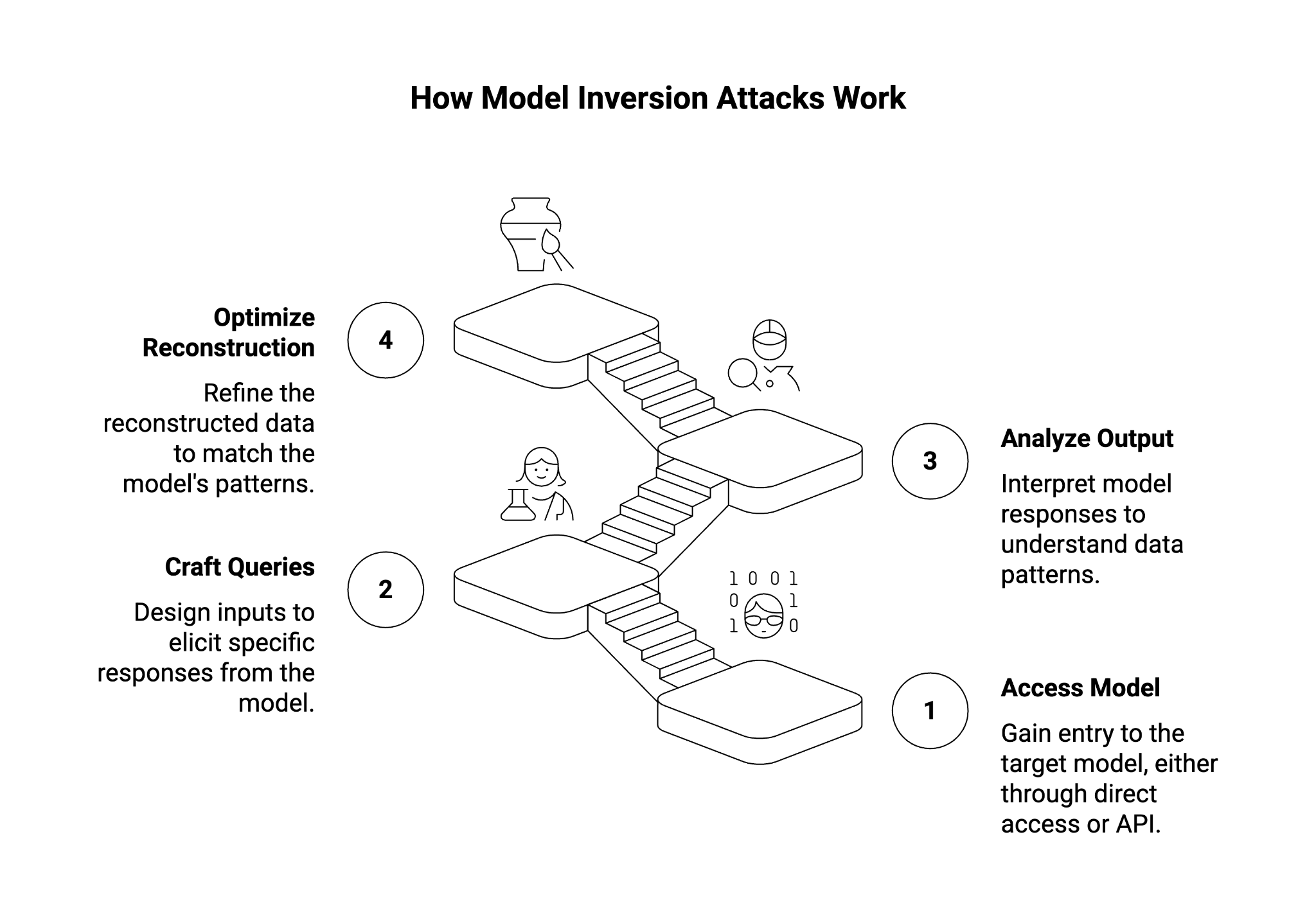
How Does a Model Inversion Attack Work?
Model inversion attacks rely on the fact that machine learning models do not merely generalize from data—they also memorize specific details from the training dataset, especially when overfitting occurs.
The attack process usually involves:
- Accessing the target model:
- In a white-box setting, attackers have access to model parameters and gradients.
- In a black-box setting, they rely on an exposed API that provides predictions or confidence scores.
- Crafting queries: Attackers submit specially designed inputs to the target model.
- Analyzing model output: By looking at confidence distributions, error rates, or even probability vectors, attackers infer which features align with actual input data used in training.
- Optimizing reconstructions: Using iterative optimization algorithms, attackers gradually approximate the sensitive data until it matches the patterns in the model.
The success of the attack depends heavily on the robustness of the model, the degree of overfitting, and the type of access available to adversaries.
Types of Model Inversion
Query-Based Attacks
In this scenario, attackers interact with a deployed model through an API. By repeatedly sending queries and monitoring model predictions, they can reconstruct details of the original training data. This approach is often used against deep neural networks deployed as public services, where only the outputs are visible.
For example, in facial recognition systems, an attacker can iteratively refine a generated face image until the model produces a high confidence score, effectively revealing characteristics of a person in the training dataset.
Membership Inference Attacks
While model inversion attempts to reconstruct input features, membership inference attacks aim to determine whether a specific data point was used during model training.
For example, given a medical diagnostic model, an adversary might infer whether a patient with a specific condition was included in the dataset. This distinction is critical:
- Model inversion = what is the data?
- Membership inference = was this data included?
Both are serious threats to data privacy but operate with different goals.
How Does Model Inversion Pose a Security Risk to AI Systems?
The risks of model inversion are profound:
- Privacy Leakage: Attackers extract sensitive attributes such as genetic markers, income levels, or medical conditions.
- Data Protection Failures: Exposed information violates GDPR, HIPAA, and other data protection regulations.
- Loss of Competitive Advantage: Proprietary datasets, once leaked, undermine a company’s investments in machine learning systems.
- Weakening of Security Posture: Model inversion can be a precursor to other AI security attacks, including adversarial attacks and model extraction.
In essence, inversion transforms AI models from protective black boxes into sources of private data leakage.
What is the Difference Between Model Inversion and Membership Inference Attacks?
The two are often mentioned together but serve different adversarial purposes:
- Model Inversion Attacks: Focus on reconstructing or recovering sensitive information about the training data. Example: guessing a patient’s health condition.
- Membership Inference Attacks: Aim to determine whether a specific data point (e.g., “John Doe’s medical record”) was part of the training dataset.
The difference lies in the granularity of information leaked. In practice, adversaries often use them in combination—first confirming that an individual was part of the dataset and then attempting to rebuild their private data.
How Can Model Inversion Attacks Be Prevented or Mitigated?
Reactive Defenses
Reactive defenses are deployed after the model is trained to limit what information is exposed:
- API Output Restrictions: Limit exposure of confidence scores, return only top-k results, or use thresholded outputs.
- Regularization Techniques: Methods like dropout and weight decay reduce overfitting, making memorization of sensitive details less likely.
- Query Monitoring: Detect abnormal query patterns (e.g., repeated fine-grained probing), which may signal black-box model inversion attempts.
Proactive Defenses
Proactive strategies build resilience into the model training process:
- Differential Privacy: Adding calibrated noise during model training ensures individual data points cannot be precisely recovered. Widely studied in academic research (see multiple arXiv and DOI-cited works).
- Federated Learning: Keeps data local and only shares model updates, reducing central points of vulnerability.
- Privacy-Preserving Algorithms: Using cryptographic approaches like secure multiparty computation or homomorphic encryption to prevent exposure of raw inputs.
- Robust Optimization: Adjusting training pipelines to balance accuracy and data protection against inversion.
When combined, these countermeasures significantly strengthen defenses against privacy leakage.
Impact of Model Inversion Attacks
The impact extends beyond theoretical demonstrations:
- Legal and Compliance Risks: Non-compliance with global data protection regulations exposes organizations to penalties.
- Reputational Damage: Organizations deploying vulnerable AI applications risk public distrust.
- Operational Risks: Leaked datasets may empower competitors or malicious actors to replicate proprietary models.
- Research Implications: Academic datasets (e.g., in healthcare or genomics) become vulnerable, discouraging open collaboration.
In short, model inversion attacks erode the foundations of trust in AI systems.
Real-World Examples of Model Inversion Attacks
- Fredrikson et al. (IEEE, 2015): The first widely cited demonstration reconstructing facial images from a facial recognition classifier.
- Ristenpart’s Group (Communications Security): Showed that genomic privacy could be compromised through inversion of genetic models.
- Recent arXiv Research: Explored gradient inversion in deep learning, where attackers use gradient information from collaborative training (e.g., federated learning) to reconstruct sensitive input images.
- GitHub Implementations: Multiple proof-of-concept codes exist online, lowering the barrier for adversaries to experiment with inversion techniques.
These examples emphasize that model inversion is not hypothetical—it is practically achievable with tools already available.
Conclusion
Model inversion attacks expose a critical vulnerability in artificial intelligence and machine learning systems. By exploiting model outputs, gradients, and overfitting, attackers can reverse-engineer sensitive data from trained models.
The difference between model inversion and membership inference attacks lies in whether adversaries are trying to reconstruct sensitive information or simply confirm membership in a dataset. Both, however, represent severe risks to data privacy and AI security.
Mitigation strategies must combine reactive defenses (API restrictions, anomaly detection, output limiting) with proactive approaches (differential privacy, federated learning, privacy-preserving algorithms). Without these measures, organizations risk data leakage, compliance violations, and reputational harm.
As the field of deep learning and artificial intelligence evolves, the focus on privacy-preserving machine learning will be central to securing sensitive information, building trust in AI applications, and ensuring compliance with modern data protection frameworks.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.