
Artificial intelligence (AI) is transforming industries from healthcare and finance to logistics and national security. Yet, while machine learning models and deep neural networks can reach extraordinary levels of accuracy, they are often criticized for being black boxes—systems that produce highly accurate predictions without revealing how those predictions were made.
This lack of transparency creates risks: biased outcomes, regulatory noncompliance, or misinformed decision-making. Model interpretability addresses this challenge by providing tools and methods to understand how AI models generate their outputs.
This guide explores what model interpretability is, why it matters, how it can be evaluated, and how organizations can implement practical interpretability techniques to make AI systems more transparent and trustworthy.
What is Model Interpretability?
Model interpretability is the ability to understand how a predictive model arrives at its decisions. It is the extent to which a human can grasp the link between input features (e.g., age, income, or medical history) and the model output (e.g., loan approval, disease prediction).
- An interpretable model is one where this link is clear, such as in a linear regression model, where coefficients directly reflect how each feature contributes to the final prediction.
- A black-box model, such as a deep neural network, may outperform simple models in accuracy but offers little clarity about which feature values or data points influenced its prediction.
Interpretability does not always mean simplicity. Sometimes, complex models can be made interpretable using post-hoc interpretability methods such as:
- LIME (Local Interpretable Model-Agnostic Explanations)
- SHAP (Shapley Additive Explanations)
- Feature importance rankings and visualizations
The core objective is not to reduce AI to something trivial but to make it sufficiently understandable for stakeholders, regulators, and end-users to trust and apply it responsibly.
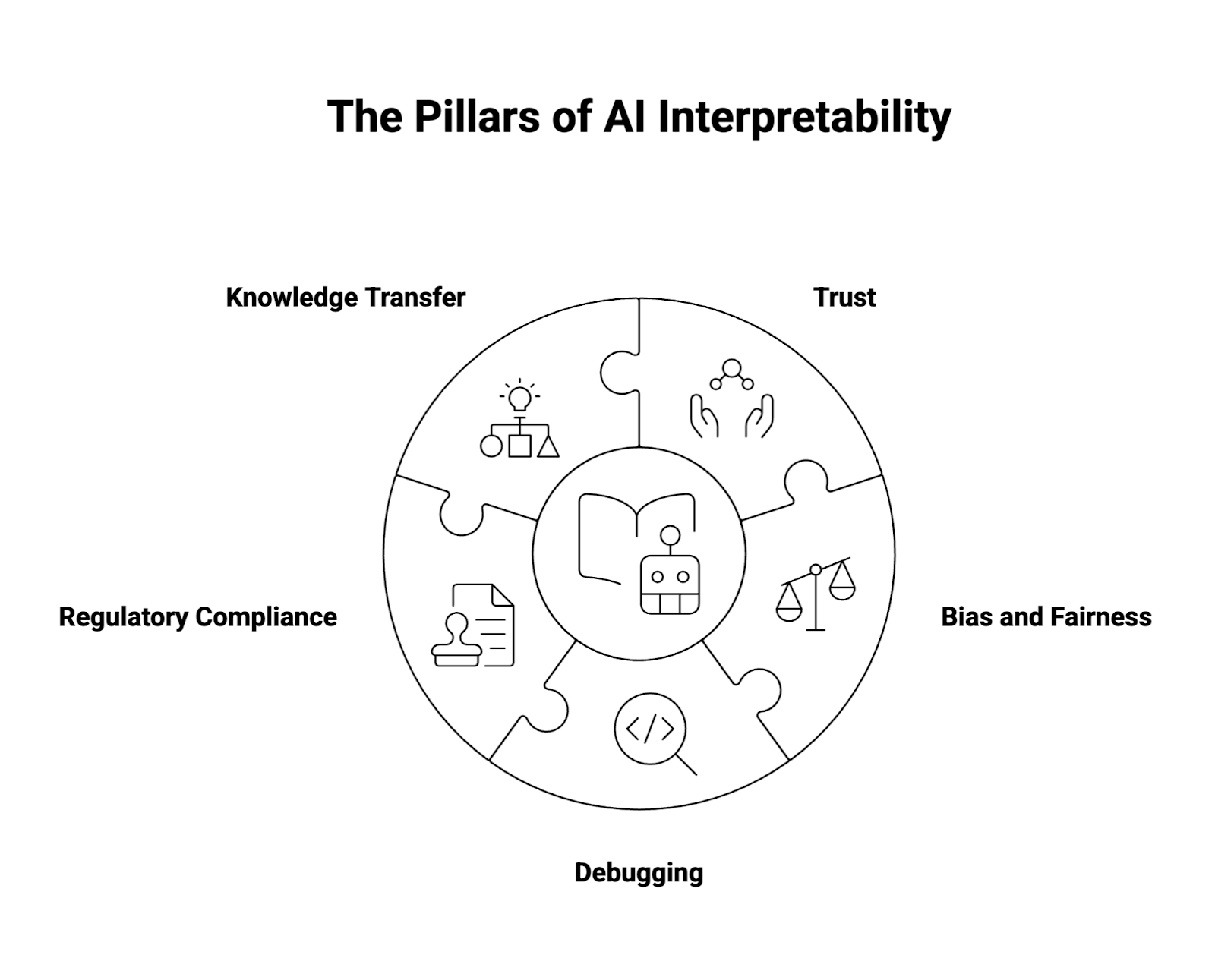
Why is AI Interpretability Important?
Interpretability is not just a research exercise—it is fundamental to AI adoption in the real world. Its importance can be grouped into five categories:
1. Trust
In high-stakes environments like healthcare, clinicians must know why an AI system flagged a tumor as malignant. If a classifier is a black box, trust erodes, and adoption stalls. Interpretability fosters confidence by showing how model behavior aligns with domain knowledge.
2. Bias and Fairness
AI models trained on flawed datasets can perpetuate discrimination. For example, a credit scoring model might unintentionally penalize applicants from minority groups if proxies for race or socioeconomic status are present in the training data. Interpretability allows organizations to detect and mitigate these biases before they cause harm.
3. Debugging
Data scientists rely on interpretability to troubleshoot errors in machine learning algorithms. If an AI predictive model starts producing unexpected model predictions, interpretable methods can help identify whether the problem lies in mislabeled data points, irrelevant features, or the structure of the trained model itself.
4. Regulatory Compliance
Regulators increasingly expect AI to be explainable. The EU’s AI Act, GDPR’s “right to explanation,” and financial oversight regulations all require organizations to justify automated decision-making. Interpretability techniques provide documentation and evidence to meet compliance obligations.
5. Knowledge Transfer
Interpretable AI enables domain experts to extract insights from machine learning models. For instance, in epidemiology, interpretable ML can highlight which environmental or demographic factors most strongly correlate with disease spread, enriching human understanding rather than just automating tasks.
How Do You Evaluate Model Interpretability?
Evaluating interpretability is challenging because it depends on context: what is interpretable to a data scientist may not be to an end-user. Still, there are structured ways to measure it.
- Human-grounded evaluation
- Non-experts are shown model explanations and asked to make judgments.
- Example: Does a doctor understand why an AI recommended one treatment over another?
- Functionally grounded evaluation
- Use measurable metrics such as fidelity, stability, and consistency.
- Example: Do explanations for similar data points yield similar results?
- Application-grounded evaluation
- Assess interpretability in specific use cases.
- Example: Does interpretability improve fraud detection accuracy when used by analysts?
Evaluation also involves trade-offs. A linear model may be highly interpretable but underperform compared to a black-box model. Organizations must weigh whether increased transparency justifies potentially lower model performance.
What Are the Properties of Interpretable Models?
An interpretable model generally exhibits the following characteristics:
- Transparency: Clear mapping between input features and model output.
- Simplicity: Easier to grasp models, such as decision trees, compared to deep learning architectures.
- Consistency: Explanations for similar subset samples should not contradict each other.
- Causality: Where possible, explanations should point toward causal rather than purely correlational relationships.
- Robustness: Interpretability must hold even if the model is exposed to noise, adversarial examples, or shifting datasets.
These properties define not just how understandable a model is but how useful its explanations are in real-world decision-making.
How Are Interpretability Methods Evaluated?
Interpretability methods themselves require evaluation. Widely used interpretability techniques include:
- Feature Importance: Ranks features by their impact on predictions.
- LIME: Builds local interpretability by approximating the black-box model with simple linear models around individual data points.
- SHAP: Uses Shapley values from game theory to fairly distribute contributions of each feature to the model output.
- Visualization techniques: Heatmaps for neural networks, tree plots for decision trees, or correlation graphs.
These methods are evaluated based on:
- Faithfulness: Does the explanation reflect the true logic of the trained model?
- Stability: Do small changes in input features result in wildly different explanations?
- Human-usefulness: Are the explanations understandable to the intended audience, whether a data scientist or an end-user?
For example, LIME may be highly intuitive for local interpretability but struggles with global faithfulness. SHAP, while mathematically rigorous, may overwhelm non-technical stakeholders with detail.
How is Model Interpretability Different from Model Explainability?
Though closely related, the two terms differ in nuance.
- Interpretability: A property of the model itself. An interpretable ML model like a linear regression or decision tree inherently reveals how it makes predictions.
- Explainability (XAI): A set of post-hoc methods and frameworks designed to explain black-box models. Techniques like SHAP and LIME fall into this category.
In practice, most organizations combine both: they use interpretable models where possible but rely on explainable AI techniques for deep neural networks and other complex models where performance is critical.
How to Make Models More Interpretable and Transparent
Improving interpretability requires deliberate choices throughout the AI lifecycle.
1. Select inherently interpretable models
- Use linear models, logistic regression, or decision trees for tasks where transparency is critical.
- For example, credit scoring often uses linear regression because regulators demand clear explanations.
2. Apply post-hoc interpretability methods
- Use LIME for local interpretability of individual predictions.
- Apply SHAP to calculate Shapley values for each feature’s contribution.
- Incorporate visualization dashboards that show feature importance and trends across datasets.
3. Balance the accuracy–interpretability trade-off
- Sometimes, a less accurate but more interpretable classifier is preferable.
- Hybrid solutions may use a black-box model for predictions and an interpretable surrogate for explanations.
4. Build interpretability into the pipeline
- Integrate interpretability during data preparation, algorithms selection, and training, rather than retrofitting it later.
- Maintain transparency about data points, transformations, and feature values.
5. Tailor explanations to stakeholders
- Data scientists may prefer technical metrics and Python outputs.
- End-users in healthcare or finance may need intuitive visualization tools that highlight risks or confidence intervals.
6. Document interpretability processes
- Maintain clear records of interpretability methods, attribution techniques, and interpretability metrics used.
- This documentation not only supports debugging but also prepares the organization for regulatory audits.
Real-World Use Cases of Model Interpretability
- Healthcare diagnostics
- A deep neural network trained on imaging data can identify cancerous lesions. By applying SHAP, clinicians can see which regions of the image influenced the prediction, increasing trust in the AI system.
- Financial risk scoring
- Banks use linear regression or decision trees to predict creditworthiness. Interpretability ensures fairness and compliance with anti-discrimination laws.
- Fraud detection
- Random forests and complex classifiers excel at spotting anomalies. Interpretability helps auditors understand why a transaction was flagged, preventing false positives.
- Customer churn prediction
- Interpretable ML highlights which features—such as service complaints or pricing changes—drive churn, helping businesses optimize retention strategies.
- Public policy
- Policymakers using AI for resource allocation need interpretable evidence to justify decisions to citizens and oversight bodies.
Conclusion
As AI models become increasingly sophisticated, the need to understand their inner workings grows in parallel. Model interpretability is not merely a technical aspiration; it is essential for trust, fairness, regulatory compliance, and effective decision-making.
By leveraging interpretable models, post-hoc interpretability methods like LIME and SHAP, and stakeholder-focused visualization tools, organizations can ensure that machine learning algorithms serve as accountable, transparent, and effective partners in real-world applications.
The future of explainable AI lies not in choosing between accuracy and transparency, but in creating systems that are both high-performing and understandable—a balance that advances not just data science, but the broader adoption of responsible AI systems.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.