
As AI becomes foundational to enterprise systems, national security, and consumer applications, a new class of threat is emerging: AI data poisoning. This insidious attack compromises the model’s training data to degrade performance, insert backdoors, or trigger malicious outcomes. For organizations building or deploying machine learning (ML) models, understanding the types of data poisoning attacks—and how to defend against them—is now a core requirement of both cybersecurity and data security strategies.
What Is AI Data Poisoning?
AI data poisoning is a form of adversarial attack in which malicious actors manipulate the training dataset of an AI model to intentionally alter its model’s outputs. These attacks introduce mislabeled, corrupted, or synthetically generated data points into the learning process to bias, destabilize, or subvert the AI system.
Unlike traditional malware or network-based intrusions, data poisoning targets the core logic of an AI model—its understanding of the world—via the data manipulation it receives during model training. Poisoning can affect both machine learning (ML) systems and generative AI models, making it a versatile and persistent threat.
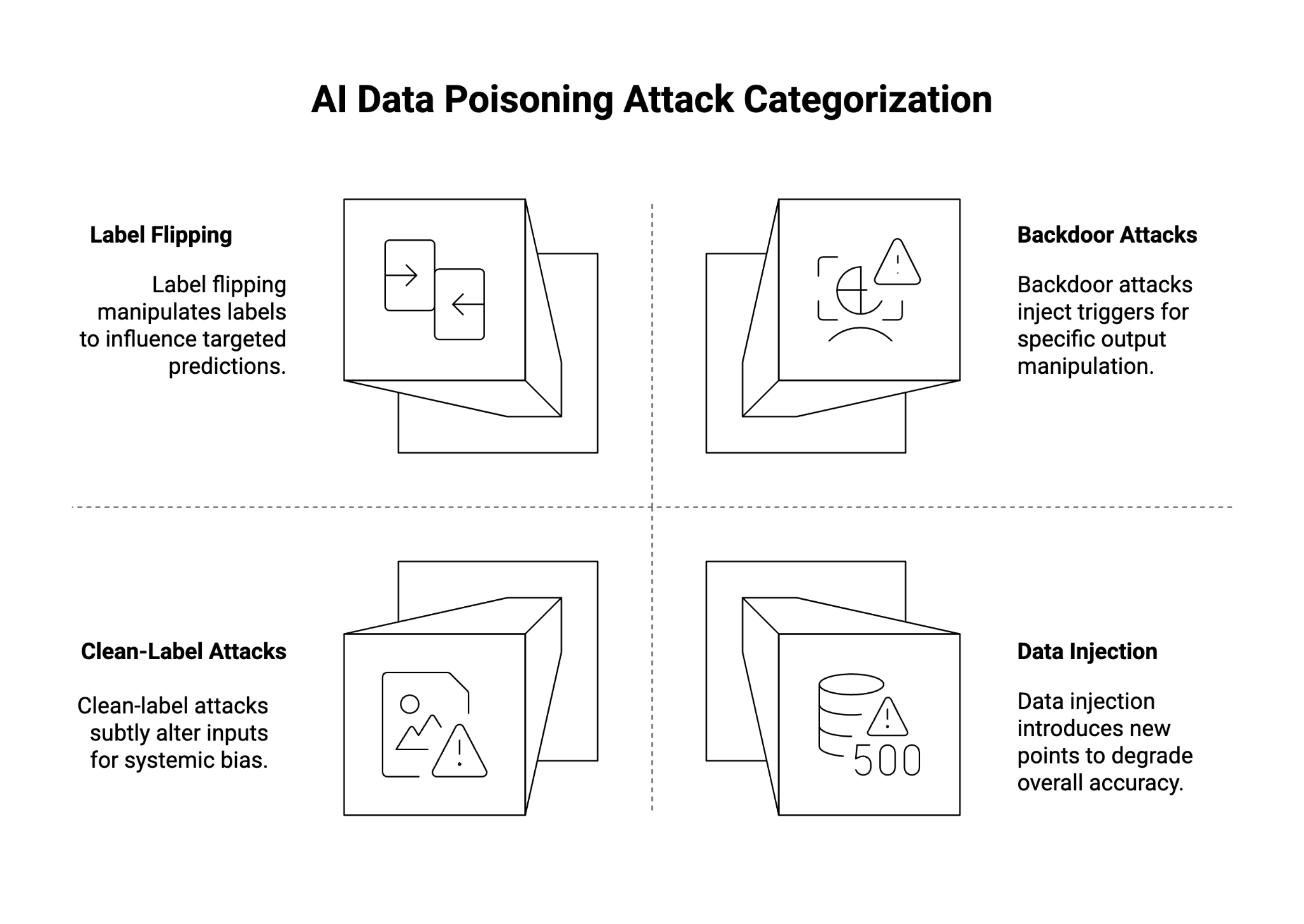
Types of AI Data Poisoning Attacks
There are several types of data poisoning attacks, each designed to exploit different vulnerabilities in ML models and training pipelines. These can be broadly categorized by method (how data is manipulated) and intent (what outcome the attacker desires).
1. Label Flipping
Attackers reverse the labels of certain samples. For instance, an image of a weapon might be labeled as “safe” instead of “threat.” When trained on such mislabeled data, the model learns dangerous false associations.
- Security Risk: Increased false negatives in high-stakes environments like surveillance or fraud detection.
- Use Case: Spam classifiers, malware detection, and facial recognition.
2. Data Injection
Malicious data is injected into the training set without altering existing entries. These new points are designed to skew the model’s decision boundary.
- Security Risk: Hidden data patterns may cause incorrect generalizations.
- Use Case: Open-source contributions, collaborative automation pipelines.
3. Backdoor Attacks
In backdoor attacks, malicious actors insert special “trigger” patterns into data (e.g., a pixel pattern or phrase). When the trigger is present at inference, the model’s outputs are manipulated—while behaving normally otherwise.
- Security Risk: Exploitable backdoors for unauthorized access.
- Use Case: Autonomous vehicles, biometric authentication, chatbots.
4. Clean-Label Attacks
These attacks use valid labels but subtly alter the inputs. For example, an image might be imperceptibly changed so that it influences the model to misclassify future inputs.
- Security Risk: Bypasses data validation checks, making detection difficult.
- Use Case: Image classifiers, document scanners, speech recognition.
Targeted vs. Nontargeted Poisoning
- Targeted attacks focus on influencing specific predictions (e.g., classifying a stop sign as a yield sign when a sticker is added).
- Nontargeted attacks aim to degrade overall accuracy or insert systemic biases.
Both approaches introduce security risks to ML systems, especially when sensitive information or safety-critical decisions are involved.
How Does Data Poisoning Affect Machine Learning Models?
The impact of data poisoning is often covert—yet profound. Because the model’s training data is compromised at the source, the attack becomes deeply embedded within the model’s logic.
Common Consequences:
- Misinformation and Bias: AI systems may make flawed recommendations in healthcare, finance, or legal contexts.
- Automation Failures: Poisoned models may malfunction within autonomous workflows, causing performance degradation or even physical harm.
- Loss of Trust: Users may lose faith in AI tools if they behave unpredictably or unethically.
- Breach of Confidentiality: Poisoned models may leak or mishandle sensitive information.
- Compliance Violations: Corrupted training datasets may lead to failures in meeting regulatory obligations (e.g., GDPR, HIPAA).
These risks are amplified in enterprise-grade ML models, where automation is deeply integrated into decision-making processes.
How Can AI Data Poisoning Be Detected?
Detecting AI data poisoning is challenging because the symptoms often emerge gradually or only under specific conditions. However, a combination of auditing and behavioral analysis can improve detection rates.
1. Data Auditing and Profiling
- Detect duplicate or outlier samples
- Identify shifts in class distributions
- Cross-check labels for inconsistencies or potential data manipulation
2. Model Behavior Monitoring
Monitor ML models for:
- Unusual confidence scores
- Prediction instability
- Drift from expected behavior on benchmark datasets
3. Explainability and Attribution Tools
Use tools like SHAP or LIME to identify unexpected feature importance patterns. If small, irrelevant changes in data are driving large shifts in predictions, it may indicate data poisoning attacks.
4. Outlier and Anomaly Detection
Apply unsupervised techniques such as:
- Isolation Forests
- DBSCAN clustering
- Autoencoders for embedding analysis
These can flag training samples that don’t conform to the dataset’s core structure.
How Can You Prevent AI Data Poisoning Attacks?
Prevention is the most effective way to reduce exposure to AI data poisoning. Below are defense strategies that should be integrated into any modern AI pipeline:
1. Implement Robust Data Validation and Sanitization
- Enforce cryptographic signatures and hashes to verify data integrity
- Remove anomalies, redundant entries, and suspicious records
- Conduct regular dataset audits, especially for crowdsourced or third-party data
2. Adversarial Training and Robust Optimization
Train models using known adversarial inputs to improve resilience:
- Use synthetic poisoned samples in training simulations
- Incorporate regularization techniques to suppress overfitting on outliers
This improves the model’s robustness to poisoned or manipulated inputs.
3. Secure the Data Supply Chain
- Vet all external data providers for credibility and security
- Secure APIs used for model training and data ingestion
- Enforce access controls to prevent unauthorized data modifications
4. Continuous Monitoring and Automation
Deploy real-time automation pipelines to:
- Log and analyze incoming data for anomalies
- Track model’s outputs for sudden performance changes
- Alert teams if unusual behavioral drift or class shifts occur
Automation reduces human error and speeds up response to emerging threats.
What Should You Do If You Suspect Data Poisoning?
- Pause Inference Pipelines
Prevent further decisions from being made by the potentially poisoned model. - Isolate Affected Datasets
Determine which batches of training data may be compromised. Compare against versioned datasets. - Retrain from Trusted Sources
Use known-clean backups or earlier model checkpoints to retrain on validated data. - Audit Logs and Access History
Identify any anomalies in data manipulation, ingestion patterns, or account activity that could point to malicious actors. - Strengthen Internal Policies
Update protocols for data contribution, labeling, and model training review cycles. - Report and Share Findings
If the attack has broader implications, report to relevant stakeholders, regulatory bodies, or AI security communities.
Examples of Real-World AI Data Poisoning Attacks
Microsoft Tay (2016)
Microsoft’s chatbot “Tay” quickly became a case study in data poisoning through real-time user input. Online users manipulated its learning by flooding it with offensive content, which it incorporated into its behavior.
BadNets (2017)
A pioneering example of backdoor attacks, where researchers added specific pixel patterns to training images that caused the model to misclassify when the pattern appeared.
Federated Learning Poisoning (2020s)
In federated learning, multiple parties contribute to a shared model. Attackers have been able to contribute poisoned data during model training, resulting in targeted model drift across the federation.
Open-source Dataset Poisoning
Some malicious actors inject false or biased entries into popular open datasets, causing widely used ML models to inherit security risks without the model developers being aware.
Conclusion
AI data poisoning is a critical and growing threat to the security, reliability, and fairness of machine learning systems. It exploits the very foundations of AI—data and learning—and can be executed silently over time, making it uniquely dangerous in high-stakes and automation-heavy environments.
Key Takeaways:
- Poisoning can be targeted or nontargeted, and include label flipping, backdoors, clean-label attacks, and more.
- The impact spans from reduced accuracy to malicious access and data leakage.
- Effective defense strategies include validation, adversarial training, automation, and access control.
- Detection requires behavioral drift monitoring, model explainability, and anomaly detection tools.
- Prevention is possible—but it requires a holistic approach to AI security, data security, and cyber hygiene.
As AI adoption accelerates, security-first AI development is no longer optional—it’s essential.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.