
What is Explainability in AI?
AI explainability refers to the degree to which the internal mechanics of an artificial intelligence system, especially those driven by complex algorithms like deep learning or large language models (LLMs), can be understood and interpreted by humans. Often framed as Explainable AI (XAI), this concept enables stakeholders to grasp how specific outputs are generated, which features were most important, and what reasoning pathways were followed.
In machine learning, explainability is especially critical when dealing with opaque or “black box” models, such as neural networks, where the decision-making process is not intuitively interpretable. Explainable AI aims to provide transparency into these systems using post-hoc explanations, interpretable models, and visualizations that illuminate model behavior, feature importance, and attribution. This clarity helps stakeholders understand not just the what, but the why behind AI decisions.
Explainability also intersects with the broader field of interpretable machine learning, which emphasizes designing models and methodologies that naturally provide insight into how model predictions are made. In domains where accountability and clarity are paramount, such as healthcare and autonomous systems, the push for explainable machine learning continues to grow.
Why is AI Explainability Important?
Ethical Implications
Ethics is a cornerstone of responsible AI development. Explainability helps mitigate bias and discrimination in model decisions by making the inner workings of algorithms visible to scrutiny. In high-stakes domains such as healthcare, finance, and criminal justice, stakeholders must understand how a model arrived at a particular decision to ensure fairness and accountability.
Key ethical benefits of explainable AI include:
- Bias Detection and Mitigation: By revealing how input data influences model outcomes, explainability exposes hidden biases.
- Fairness and Equity: Ensures that decisions do not disproportionately affect specific groups.
- Human Oversight: Supports human-in-the-loop decision-making where AI augments rather than replaces human judgment.
- Transparency: Facilitates ethical audits and external reviews by making algorithms interpretable.
Without explainability, decisions made by AI systems may inadvertently reinforce societal inequities due to biased training data or flawed model assumptions. Explainable artificial intelligence empowers organizations to uphold accountability and non-discrimination.
Business Impacts
From a business perspective, AI explainability is essential for building user trust, ensuring compliance, and optimizing performance. Customers and end-users are more likely to adopt AI technologies when they understand the rationale behind predictions.
Key business advantages of explainable AI include:
- User Trust: Clear explanations of AI decisions increase user confidence and engagement.
- Debugging and Optimization: Facilitates model refinement by highlighting important features and identifying flaws in training data or methodology.
- Governance and Risk Management: Supports model monitoring, auditing, and accountability throughout the AI lifecycle.
- Competitive Differentiation: Organizations demonstrating transparency may gain market trust and regulatory advantages.
Explainability contributes directly to model governance by increasing transparency and reducing operational risk. It enables businesses to align AI operations with stakeholder expectations and regulatory frameworks.
Moreover, in regulated industries such as healthcare and finance, explainability is critical for meeting legal requirements, including the General Data Protection Regulation (GDPR) in the European Union, which mandates that individuals have a right to an explanation of automated decisions. This is especially relevant for AI use cases involving sensitive or high-impact decisions, such as insurance underwriting, loan approvals, and medical diagnoses.
What is an Example of Explainable AI Techniques?
A variety of explainability methods have been developed to illuminate the inner workings of complex AI models. These methods can be broadly categorized into two types: intrinsic (where the model is inherently interpretable) and post-hoc (where explanations are generated after model training).
Prominent Examples
- LIME (Local Interpretable Model-Agnostic Explanations): LIME provides local explanations for individual predictions by approximating the complex model with an interpretable model, such as linear regression or decision trees, in the vicinity of the input data point. This helps end-users understand why the model behaved a certain way for specific cases.
- SHAP (SHapley Additive exPlanations): Based on game theory, SHAP assigns each feature a contribution value for a specific prediction, helping users understand feature importance with a strong theoretical foundation. SHAP values provide both local and global interpretability, enabling analysis of individual predictions and overall model behavior.
- Counterfactual Explanations: These show how small changes in the input data could lead to a different outcome, helping to clarify the sensitivity of model predictions. For example, a loan application denial could be explained by showing what changes in income or credit score would result in approval.
- Visualization Techniques: Tools such as saliency maps, Grad-CAM, or attention heatmaps are used in deep learning models to highlight which parts of an input (like an image or text) influenced a particular decision. These visualizations offer intuitive insights into model focus and reasoning.
- Interpretable Models: Models like decision trees, linear regression, and rule-based systems are inherently interpretable and often used when explainability is prioritized over accuracy. These models are especially useful for prototyping, compliance, and high-stakes applications.
- Feature Importance Analysis: Many ML frameworks provide built-in methods for calculating global or local feature importance, helping developers assess which inputs contribute most significantly to predictions.
These techniques are often used in tandem to ensure both comprehensiveness and clarity in explaining model predictions and behaviors.
How Can AI Explainability Improve Trust in AI Systems?
Transparency and Trust
Transparent AI systems foster user trust by making the decision-making process visible and understandable. When stakeholders can see how a model arrived at its output, they are more likely to accept its recommendations. This is particularly important in real-world use cases such as loan approvals, diagnostic tools, or hiring platforms, where the consequences of AI decisions are significant.
Explainable machine learning allows data scientists and end-users to inspect model behavior, identify potential failure points, and assess whether the system aligns with human reasoning. This insight supports responsible AI and encourages broader adoption across industries.
Trust is further enhanced when explanations are contextualized for the user’s domain and level of expertise. For instance, in healthcare, an AI system might highlight which symptoms or test results contributed to a diagnosis, allowing clinicians to validate the reasoning using their own expertise.
Compliance and Regulation
Regulatory bodies are increasingly focused on ensuring that AI systems operate transparently and fairly. The GDPR, for instance, requires that companies using automated decision-making provide meaningful information about the logic involved. Explainability methods help organizations comply with such regulations by producing interpretable outputs and traceable decision pathways.
In the United States and European Union, policymakers are also developing AI-specific regulations that emphasize the need for transparency, especially in high-risk applications. The European Union’s AI Act introduces mandatory risk assessments and transparency requirements for AI systems deemed high-risk.
Explainability is also critical for certification and audit processes, where third-party reviewers need to understand and verify model performance, safety, and fairness metrics. By integrating explainability from the start, organizations reduce the burden of retroactive justification and simplify regulatory approvals.
Explainability and Adversarial Attacks
Explainability can play a dual role in the context of adversarial attacks. On one hand, it helps developers detect vulnerabilities in AI systems by making unusual model behavior more observable. On the other, it can be exploited by attackers to reverse-engineer models or design inputs that evade detection.
For example, by analyzing model decisions through attribution methods like SHAP or LIME, an attacker might identify weak points in the decision boundary and craft adversarial examples that manipulate model predictions. To counteract this, organizations must strike a balance between transparency and security, incorporating adversarial robustness into their explainable AI strategies.
Explainability also aids in debugging and defending against adversarial attacks by enabling a clear view of how inputs are processed and where perturbations might lead to misclassifications. By integrating explainability with robustness testing, organizations can proactively identify and mitigate attack vectors before deployment.
Furthermore, research from arXiv and academic institutions continues to explore how explainability methods can be adapted to support both interpretability and resilience against manipulation, paving the way for secure, explainable artificial intelligence.
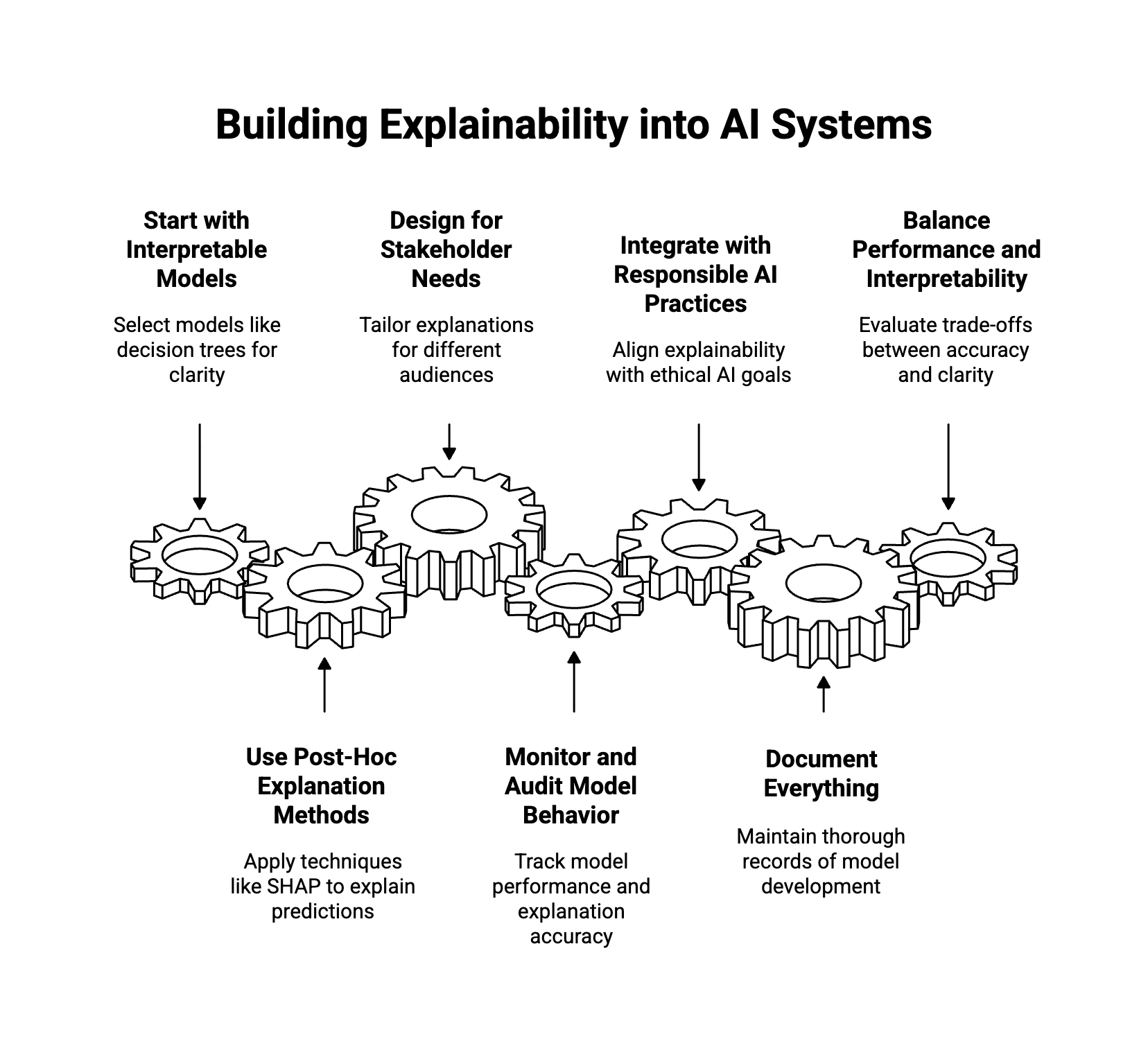
How to Build Explainability Into Your AI Systems
Incorporating explainability into AI systems requires a systematic approach that spans the entire AI development lifecycle. Below are recommended steps and best practices:
1. Start with Interpretable Models
- Use interpretable machine learning models such as decision trees, logistic regression, or linear models when possible.
- For high-stakes or regulated use cases, prioritize models that offer clarity over black-box performance.
- Select algorithms that provide both predictive power and transparency to optimize model behavior and user trust.
2. Use Post-Hoc Explanation Methods
- Apply techniques like SHAP, LIME, or counterfactual analysis to explain predictions from complex models.
- Implement visualizations to display how features affect outputs in real time.
- Choose tools that align with the nature of your data and the sophistication of your users.
3. Design for Stakeholder Needs
- Tailor explanations to different audiences, such as data scientists, compliance officers, and end-users.
- Ensure that explanations are not only technically accurate but also understandable to non-experts.
- Provide local explanations for individual decisions and global explanations for overall model trends.
4. Monitor and Audit Model Behavior
- Integrate explainability into model monitoring and validation processes.
- Use metrics to track model performance and explanation accuracy throughout the lifecycle.
- Conduct regular audits to detect changes in feature importance or potential drift in model predictions.
5. Integrate with Responsible AI Practices
- Align explainability initiatives with broader responsible AI goals, including fairness, accountability, and transparency.
- Include explainability reviews in ethical assessments and risk audits.
- Develop cross-functional governance teams to oversee explainable AI development and deployment.
6. Document Everything
- Maintain thorough documentation of model development, explainability methods used, feature selection, and model decisions.
- Use frameworks and tools from organizations like IBM, Google, and Microsoft to standardize practices.
- Keep a record of model changes, retraining procedures, and rationale for feature engineering.
7. Balance Performance and Interpretability
- Evaluate the trade-offs between model accuracy and interpretability.
- Use hybrid approaches that combine interpretable models for decision support with more complex models for prediction.
- Leverage ensemble methods where one model provides predictions and another offers interpretable approximations.
Conclusion
AI explainability is no longer optional; it is a foundational requirement for deploying safe, ethical, and trustworthy AI systems. Whether addressing compliance under GDPR, debugging deep learning models, or ensuring stakeholder trust, explainable artificial intelligence (XAI) enhances both the development and application of AI technologies. By integrating explainability methods like SHAP, LIME, and counterfactual reasoning into machine learning workflows, organizations can illuminate the inner workings of even the most complex AI systems.
As AI continues to impact high-stakes, real-world domains, the demand for transparency will only grow. Companies that proactively build explainability into their AI development lifecycle will not only meet regulatory requirements but also differentiate themselves through responsible innovation. They will build trust among end-users, improve model performance, and mitigate risks associated with opaque decision-making.
Explainability is not a one-time feature but an ongoing commitment to transparency, fairness, and accountability in the use of AI technologies. The future of AI will depend not just on the power of algorithms but on our ability to understand, interpret, and govern them effectively.
About WitnessAI
WitnessAI is the confidence layer for enterprise AI, providing the unified platform to observe, control, and protect all AI activity. We govern your entire workforce, human employees and AI agents alike, with network-level visibility and intent-based controls. We deliver runtime security for models, applications, and agents. Our single-tenant architecture ensures data sovereignty and compliance. Learn more at witness.ai.